
[vSphere with Tanzu][Homelab] Como arreglar un cluster supervisor atascado en «Removing»

[vSphere with Tanzu][Homelab] Como arreglar un cluster supervisor atascado en «Removing»
Durante la implementación de Tanzu en mi home-lab, el proceso falló por falta de recursos en uno de mis nodos ESX Nested, por lo que procedí a desactivar el cluster supervisor para solucionarlo y posteriormente volver a configurarlo.
El problema, es que el cluster se quedó atascado en «Removing» siendo totalmente imposible avanzar a otro estado.

Síntomas
- Cluster supervisor en estado «Removing» durante horas

- Resource pool «Namespaces» y VMs de Supervisor atascadas, pues no tenemos permisos para eliminarlas al ser un objecto gestionado por el propio ESX Agent Manager.
- En mi caso, al estar usando NSX como balanceador de Tanzu, elementos atascados en NSX, como un T1, segmentos y balanceadores de carga que tampoco pueden ser eliminados por el usuario admin (es posible hacerlo forzosamente desde la API, pero no es la finalidad de este post, escribiré sobre ello en el futuro).
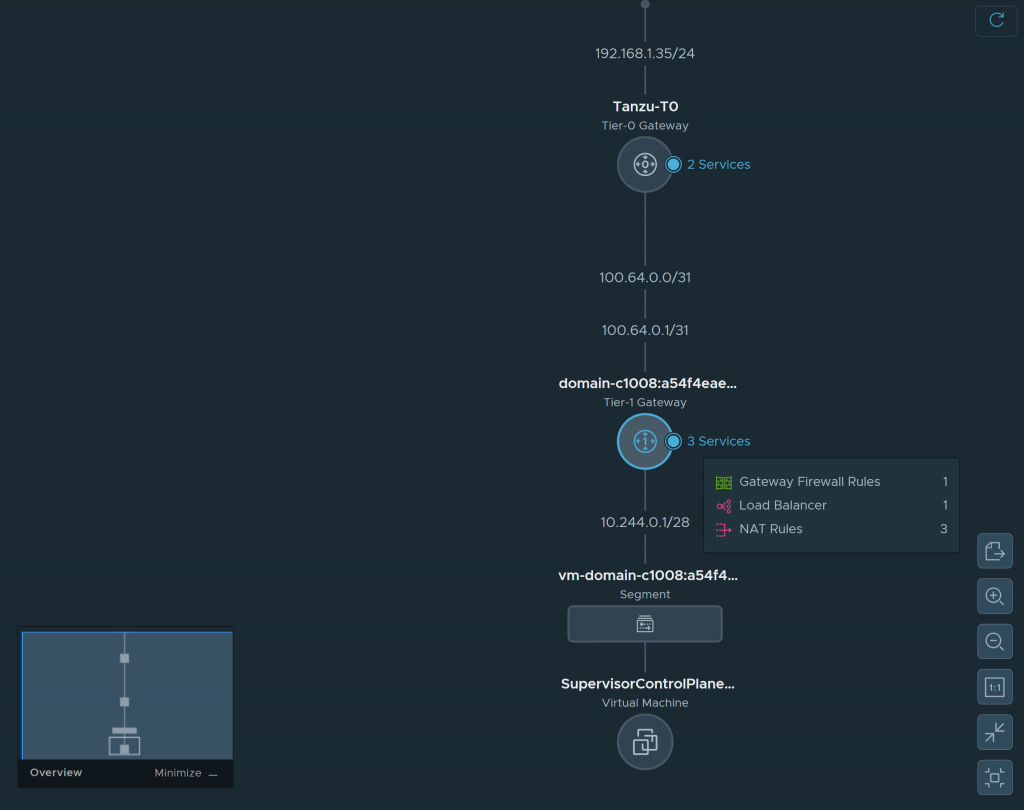
- En los logs del proceso wcp (/var/log/vmware/wcpsvc.log) podemos ver el mensaje: Unable to disable cluster domain-xxxxx. Err <nil> de manera constante durante horas, indicando que el proceso de eliminación está en bucle.
Troubleshooting realizado sin éxito
- Reiniciar el servicio wcp: Mismo resultado
- Reiniciar el vCenter: Mismo resultado
- Reinicio completo de vCenter y nodos: Mismo resultado
- Eliminar manualmente la VM de Supervisor desde el host ESX: La VM queda orphaned, mismo resultado
- Tratar de desactivar el cluster desde PowerCli: El proceso no avanza del 0%
- Tratar de eliminar la resource pool «Namespaces» desde PowerCli y desde API: Sin permisos
- Buscar en foros y comunidad VMware: Alguna gente reportaba problemas similares pero sin solución.
Parecía que mi única opción era la de desplegar un vCenter server nuevo y empezar desde cero, pero ya que esto se trataba de un laboratorio, ¿Por qué no aprovechar la ocasión para romperlo un poco más e investigar? 😜😜, y así fue como dí con la solución:
Solución:
Por favor NO intentes hacer esto en un entorno de producción, ya que vamos a trabajar sobre la base de datos de vCenter directamente y podríamos dejarlo inservible o parcialmente corrupto. Si tienes un entorno de producción y algún problema de este tipo, abre un caso de soporte con VMware en lugar de continuar con esta guía. Este trobleshooting ha sido totalmente casero, diseñado para un home-lab y no se encuentra soportado por VMware. Este post está dedicado a gente que quiera «enredar» para aprender.
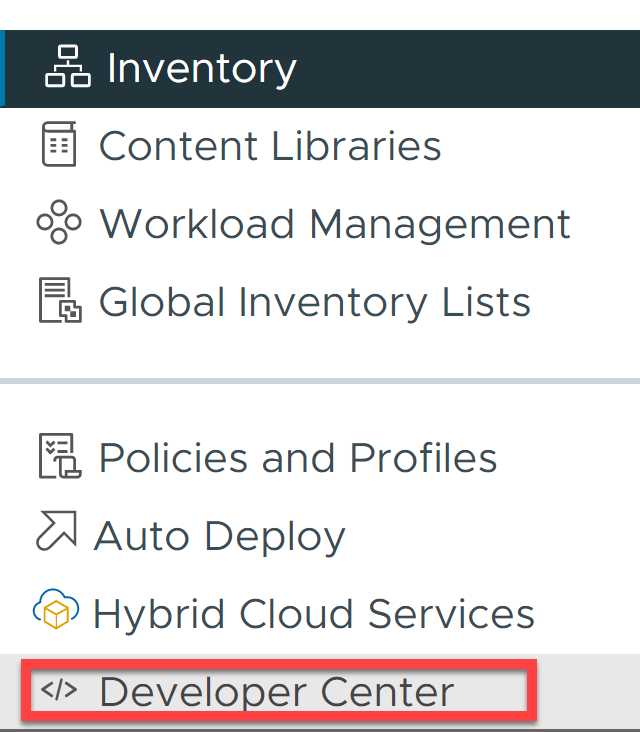
Paso 1: Obteniendo el ID del resource pool «Namespaces» mediante el API explorer.
El primer paso, será obtener el identificador del resource pool «Namespaces» utilizando el API Explorer de vCenter. Para ello, sobre el menú principal pulsaremos en «Developer Center»
Una vez dentro pulsaremos en «Api Explorer», en el cuadro de búsqueda escribiremos «resource pool» y ejecutaremos el GET sobre /api/vcenter/resource-pool
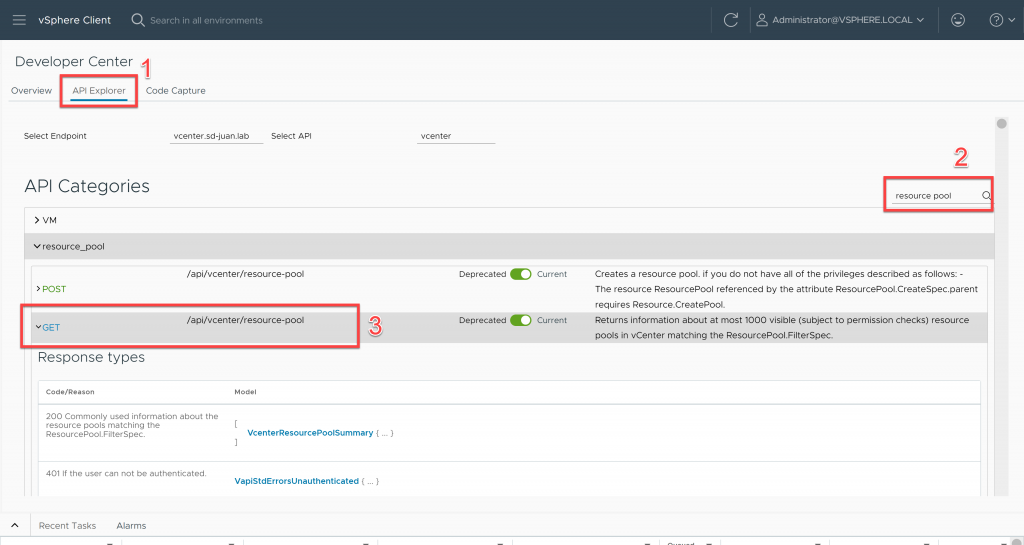

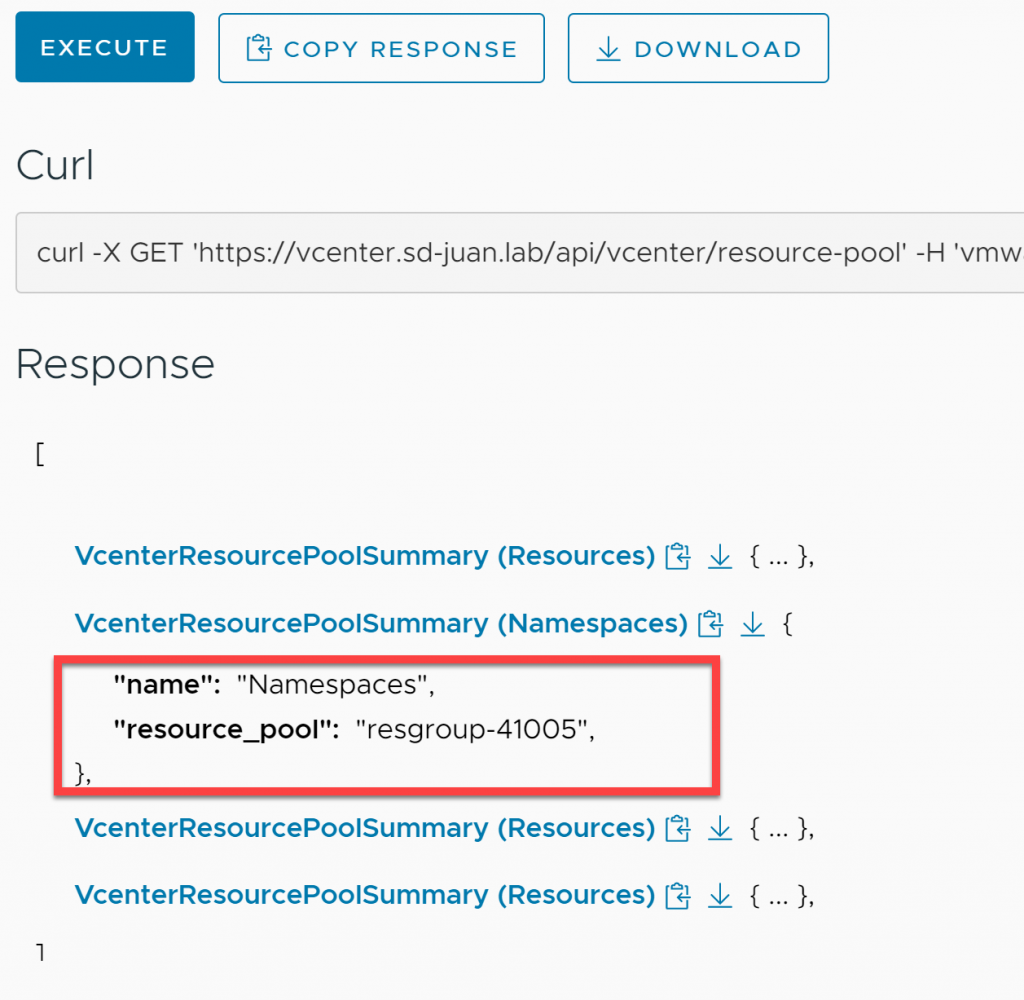
Una vez tengamos la respuesta de la ejecución del comando, expandimos el resouce pool «Namespaces» y apuntamos el número de resgroup (en este caso 41005)
Paso 2: Parando los servicios wcp y vpxd
El siguiente paso será parar los servicios wcp (Workload Control Plane) y VPXD (Virtual Provisioning X Daemon). Debemos de tener en cuenta que mientras el servicio VPXD esté parado, nuestro vCenter será inaccesible.
Nos conectamos por ssh al vCenter como root y ejecutamos un shell.
Una vez dentro, lanzamos los siguientes comandos:
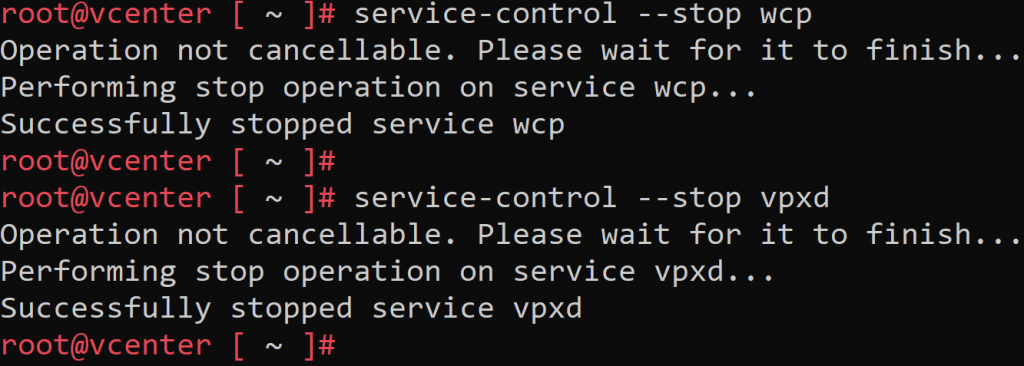
service-control --stop wcp service-control --stop vpxd
Paso 3: Sacando un backup de la base de datos PSQL de vCenter
Como vamos a tocar sobre la base de datos de vCenter, el primer paso será obtener un backup, para poder restaurarlo en caso de problemas:
/opt/vmware/vpostgres/13/bin/pg_dump VCDB -U postgres > VCDB-db-bck.sql
Comprobamos que el backup tiene un tamaño razonable, y opcionalmente por seguridad, podemos proceder a descargarlo con alguna herramienta como Winscp:

Paso 4: Conectandonos a la base de datos de vCenter y eliminando los elementos de wcp y resource pool
A continuación, nos conectaremos a la base de datos PSQL del vCenter y eliminaremos las columnas que refieren a la entidad del resource pool «Namespaces», así como a la configuración del cluster supervisor. Si bien no eliminaremos todo y la base de datos quedará sucia, eliminaremos lo suficiente para que esta pueda ser correctamente limpiada por vCenter en próximos pasos.
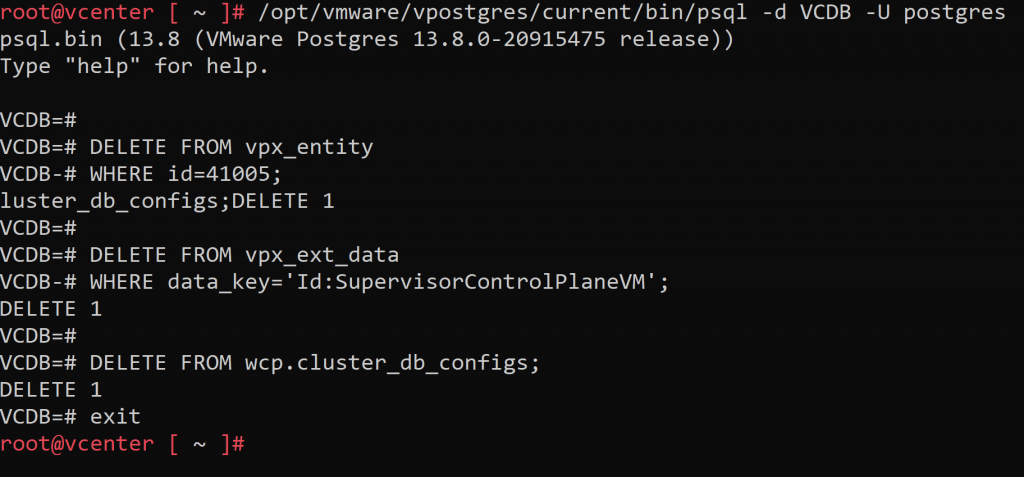
En primer lugar, reemplazaremos en el siguiente código el campo RESOURCEPOOLID por el número de resource group apuntado en el paso 1:
/opt/vmware/vpostgres/current/bin/psql -d VCDB -U postgres
DELETE FROM vpx_entity
WHERE id=RESOURCEPOOLID;
DELETE FROM vpx_ext_data
WHERE data_key='Id:SupervisorControlPlaneVM';
DELETE FROM wcp.cluster_db_configs;
exit
Por favor, tened en cuenta que este comando eliminará todas las instancias de cluster supervisor disponibles en el vCenter, en caso de tener más de una instancia, será necesario eliminar únicamente el cluster afectado en la tabla wcp.cluster_db_configs.
Una vez reemplazado el id, lanzamos el comando desde el shell de root abierto previamente:
Paso 5: Borrando manualmente las SupervisorControlPlaneVMs
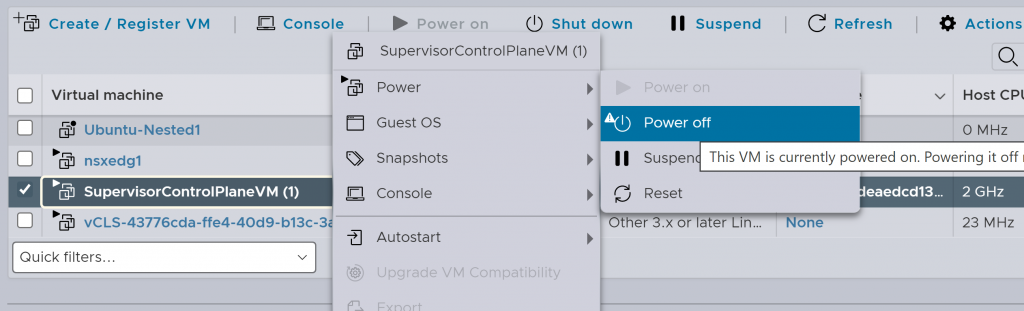
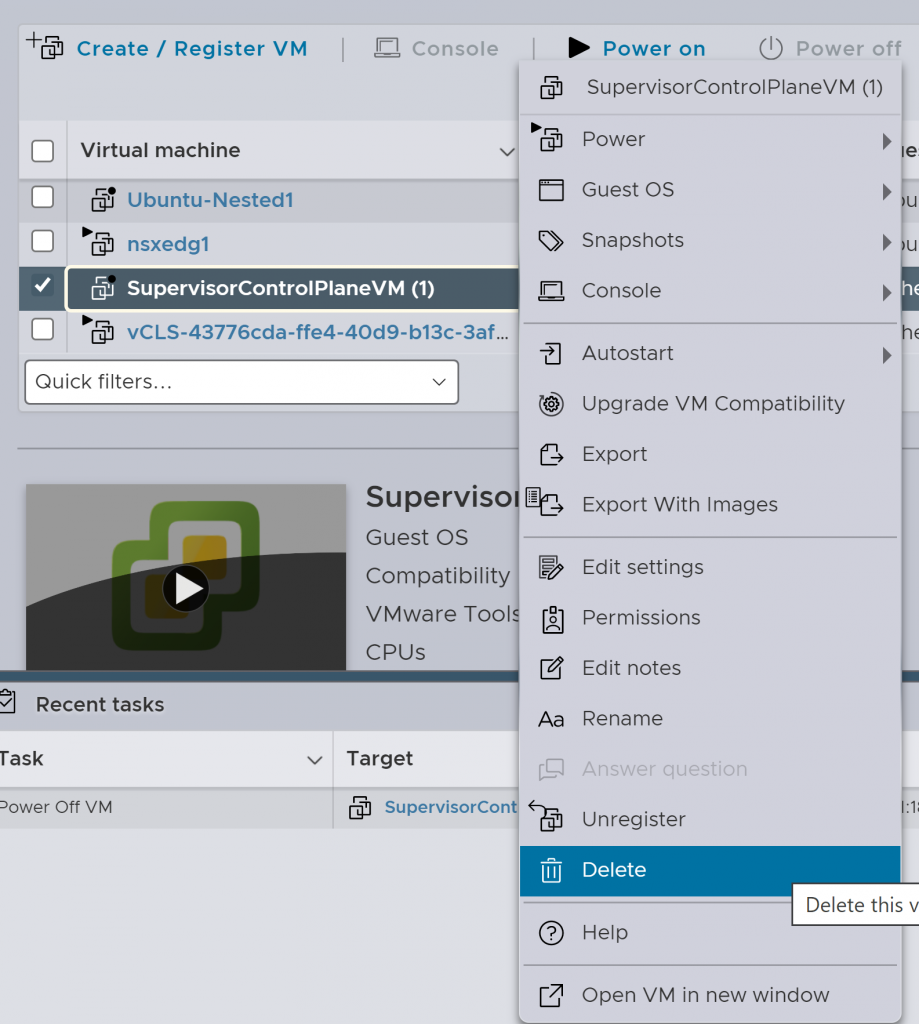
A continuación, eliminaremos a mano las SupervisorControlPlaneVMs de los hipervisores, para ello iremos a cada uno de los ESXi que contenga estas VMs y primero las apagaremos, posteriormente las eliminaremos:
Paso 6: Levantando los servicios wcp y vpxd, y eliminando las SupervisorControlPlane VMs del inventario.
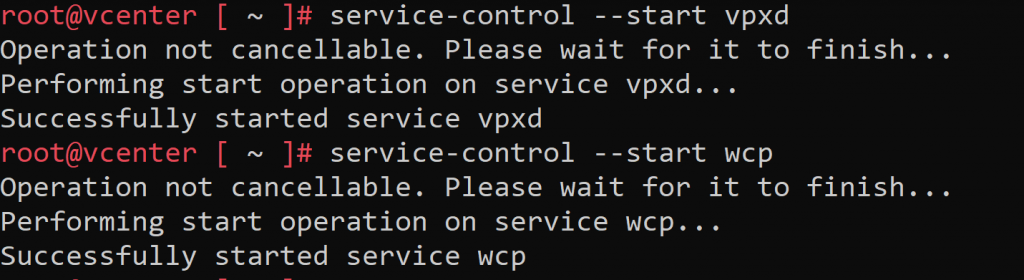
Procedemos a levantar los servicios que paramos en el paso 2, lanzando sobre un shell de root de vCenter los comandos:
service-control --start vpxd service-control --start wcp
Volvemos a nuestro vCenter, y veremos que tanto el resource pool de Namespaces, como la configuración del cluster supervisor han desaparecido, sin embargo la SuperVisorControlPlane VM sigue apareciendo como «orphaned», en la barra de tareas podemos ver varios intentos de instalación de agente fallidos, y en NSX (en mi caso) persigue la configuración del cluster:
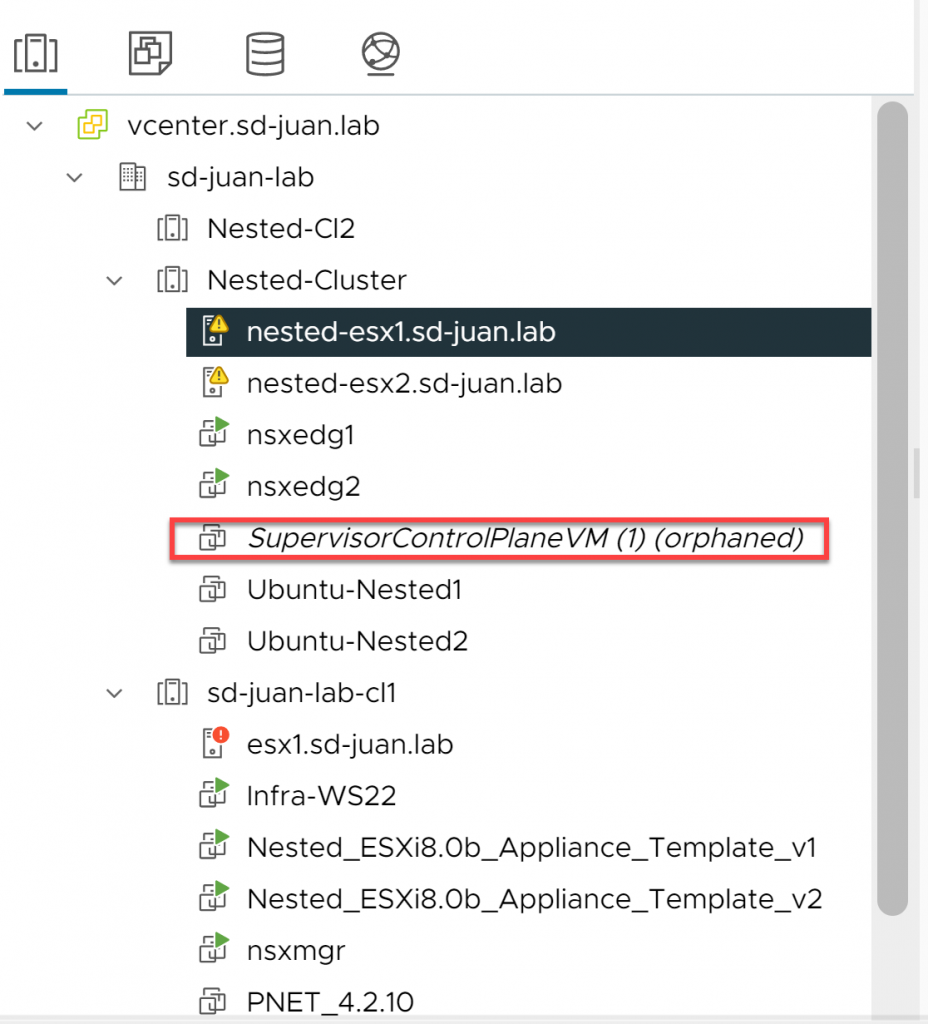
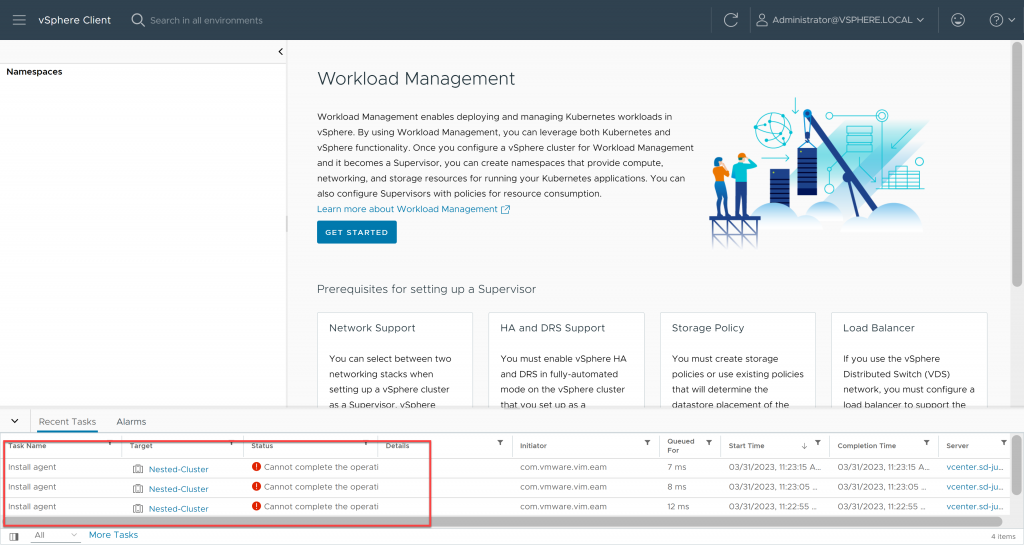
Sin embargo, ahora tenemos la opción de quitar la SupervisorControlPlane del inventario, haciéndole click con el botón derecho y pulsando en «Remove From Inventory». Por lo que lo hacemos.
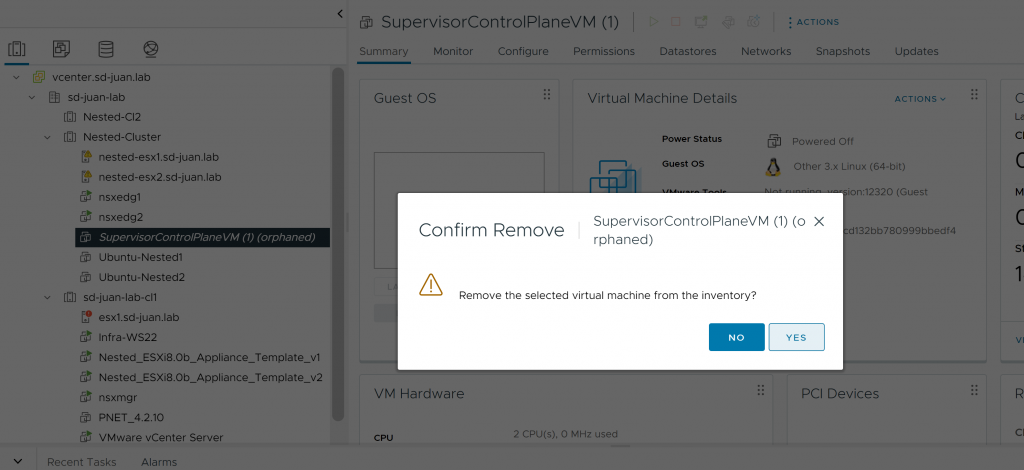
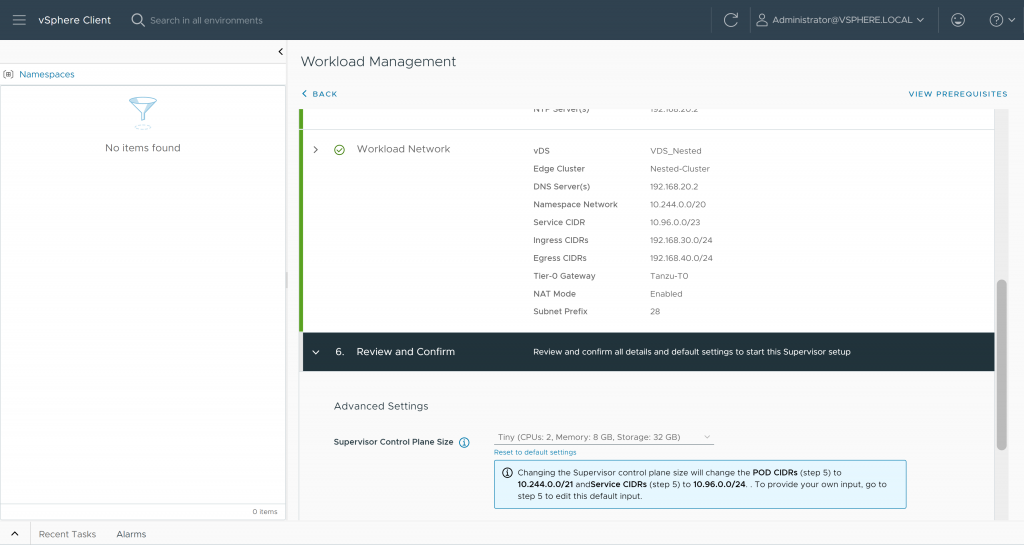
Paso 7: Reconfigurando y re-desactivando el cluster
El último paso, será tratar de reconfigurar el cluster Supervisor desde el menú de Workload Management, por lo que accedemos e introducimos todos los parámetros de configuración de éste y lanzamos su despliegue:
Enseguida recibiremos un error, indicando que no se puede desplegar el cluster:
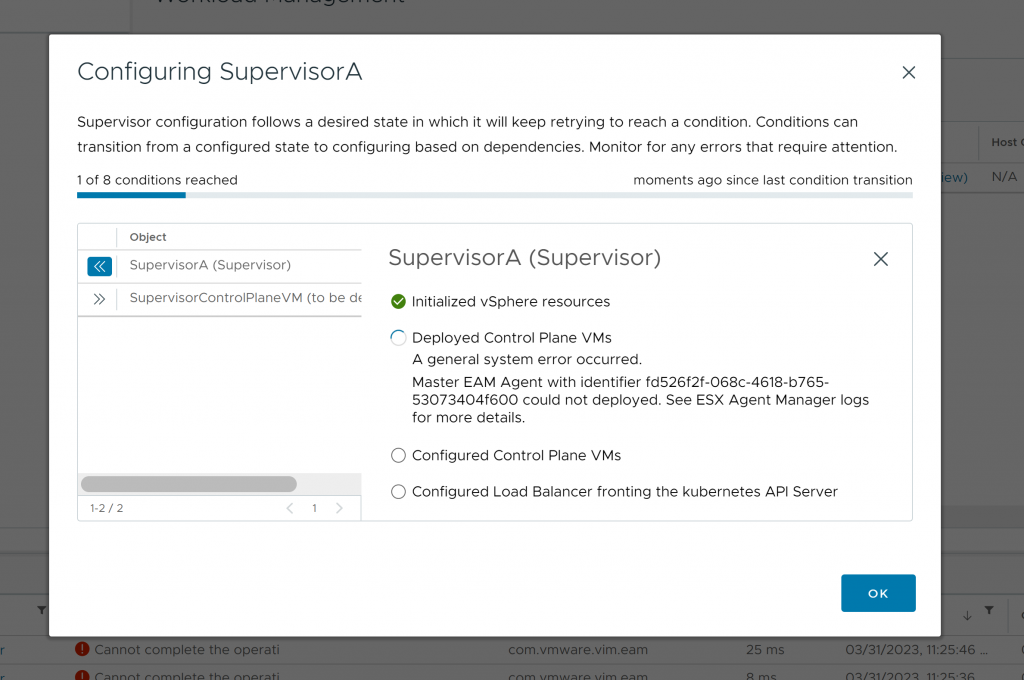
Será en este momento, cuando procederemos a la desactivación nuevamente del mismo:
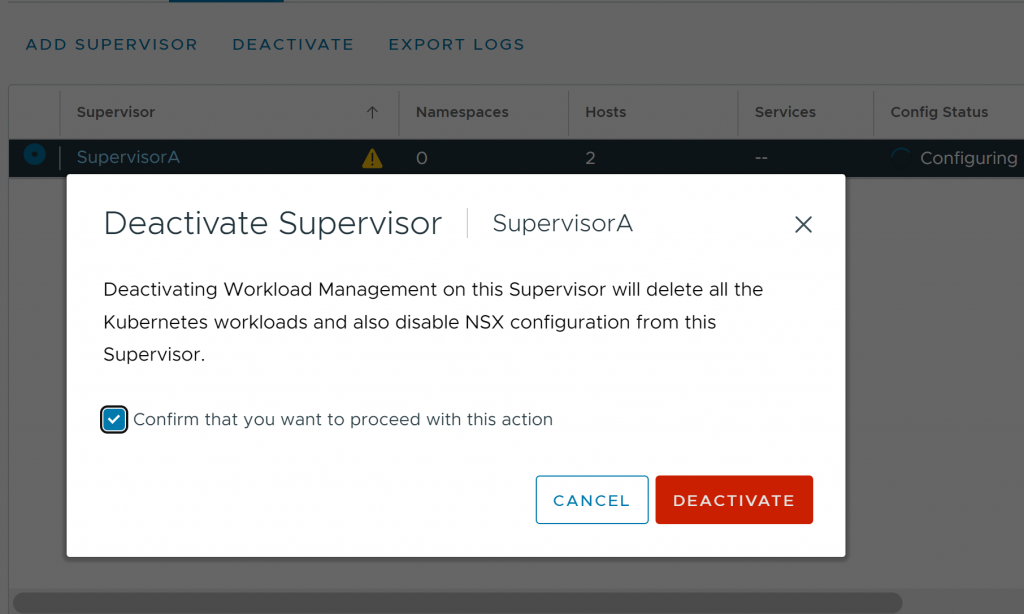
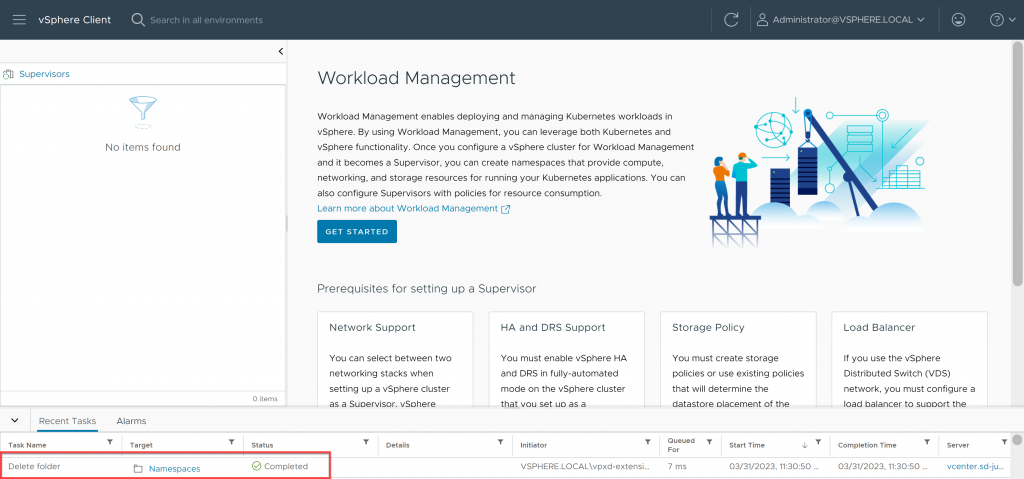
¡Eureka! Pasados unos minutos, el cluster estará desactivado correctamente, eliminando toda la configuración residual restante (NSX, Agentes de host…) y por lo tanto quitando todos los errores de vCenter.
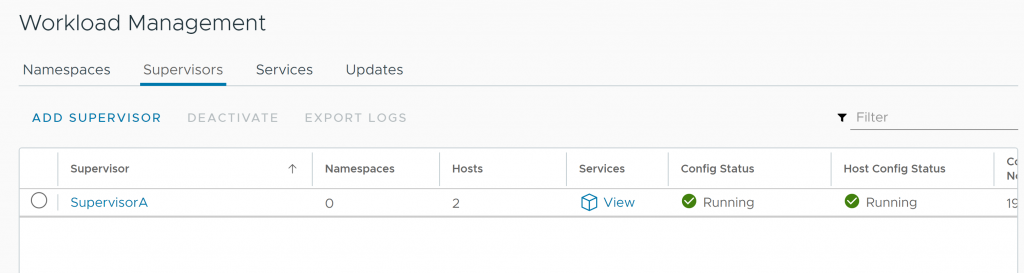
Bonus: Cluster Supervisor redesplegado correctamente
Tras la realización de estos pasos, pude desplegar correctamente de nuevo mi cluster Supervisor sin tener que reinstalar el vCenter, por lo que parece que la base de datos no quedó muy «tocada» 😜
Como siempre, ¡Espero que os haya gustado y que os resulte de utilidad a todos los que queréis aprender! ¡Nos seguimos leyendo!.